PyGI is a project, which implements dynamic bindings to GObject based libraries for Python using GObject Introspection. Initially, it was a separate project, these days it is merged into main PyGObect. If you read my previous posts, this is kinda what we want to implement for PHP in GObject for PHP project, but for Python.
For the project, I used Python 3. This choice led to the requirement of installing latest versions of software, but the good news is, that coming Ubuntu Natty has a good initial set of software. So, I had to install:
- Python 3.1 (3.2 should work too)
- GObject Introspection 0.10.x
- PyGObject 2.28.0 (2.27.x-dev series are ok too)
- If you plan to work with ØMQ, as I did, be sure to grab PyZMQ 2.1 series (easy_install will probably work)
The main library, I worked with — libmidgard2 — supports GObject introspection, so I didn’t need to install anything python-related to make it work.
Ok. Here are some hints on coding using PyGI.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
But, novice Git users don’t know how to do this optimally, and “naive” approach leads to complexities. Git is a distributed version control system, which means that everyone can “commit” to their copies of repositories. Syncing these commits with upstream is a bit more difficult and leads to commit-conflicts sometimes. So, here’s aforementioned “naive” approach:
- Fork upstream github repository
- Clone forked repository to local machine
- Make changes
- Commit
- Push
- Send Pull Request
It will work, but, there’s one non-obvious thing: pull request, probably, won’t be merged immediately and there are high chances, that there will be some commits commits pushed to official repository before our commit is merged. As the result, we have a conflict between upstream repository and our forked repository. So, at this point, if we plan to use our forked repository again, we have to “merge” upstream changes. It’s not end of the world, and git, if we’re lucky enough, will do this merge automatically as part of ”git pull upstream”, but it won’t be “fast-forward” merge and github’s ”Network” diagram (or branches diagram in your favourite git GUI) won’t be nice and clean anymore.
There’s better approach, and it’s name is ”Feature Branches”. It’s quite simple. Once you have cloned forked repository (i.e. after steps 1-2), use ”git checkout -b new_branch_name” command (it’s nice, if “new_branch_name” summarises changes you’re going to implement). This command creates new branch, starting from current “master” and makes it active. Make changes and commit them: “master” branch is left intact and all the things you changed sit nicely in this new branch. Now, push these changes with ”git push origin new_branch_name” command. This will send your new branch to github. Now, open this branch on github and send Pull Request from your “new_branch_name” to upstream’s “master”, as usually.
Use ”git checkout master” to return to the “master” branch, and, whenever upstream merges your changes, and you pull those, they will appear here automatically, without a single “merge” effort from you. As a bonus, you get beautiful tree of branches without complex knots.
1. That is a great addition to the standard PHP tool-set. I remember days, when I had to configure web-servers to run my web-projects and it was ridiculously distracting. It’s not “rocket science”, but still complicates matters a lot. Finally, developers would be able to forget about these monstrous WAMP/XAMPP/whatever packages and just run their applications using “php -S localhost:8080”.
2. Dear developers, please, do not expect this to handle production load. This web-server is solely for localhost developer needs. It is a single-process, single-threaded, blocking http-server.
3. If you’re looking for the solution, which is similar Ruby’s Rack or Python’s WSGI this is not it. But AiP (formerly ”AppServer in PHP”) is: it lets your application pre-initialize classes (and keep them in memory between requests), pre-open database connections, pre-warm caches, etc. and serve application with a fast multi-processed server (you can choose from HTTP, SCGI and ØMQ/Mongrel2 protocols). And it is still as easy to start bundled http-server: “aip app path/to/application”
Various versions of AiP are used in production on several large projects and show nice results (it is stable and really fast). And we’re planning to release next major version really soon now. If that sounds interesting, join our discussion group and watch the project on github
]]>I didn’t mention this project on blog, but that is only because I wasn’t blogging much lately. :)
It’s been in the news, that PHP-GTK ”is being split up into different projects, PECL/Cairo, GLib, GObject, etc”, but there were not many details on these changes. It’s time to fill the gap.
I was working on “GObject” part from the list. Our idea is to get rid of legacy code, target php 5.3+ and build highly modular system, which would be easy to extend and maintain.
This new PHP extension is called “GObject for PHP”, so, my main concern, obviously is building comfortable bridge between GObject objects and PHP’s objects. It starts to work, but there’s a lot of stuff to be done. Please join the project, if you are interested. We need more hands! :) Anyway, here’s what is done:
“master” branch
I started my implementation with “master” branch. I see it as a common ground for various specific php extensions wrapping gobject libraries. For example, Mark Skilbeck implemented libnotify binding this way. Eventually, new generation of GTK+ bindings could be implemented in similar fashion.
At the moment I have PHP counterparts of the following parts of GObject world:
- GType — implemented as GObject\Type. This is the scaffolding, which is used for creating new classes in runtime.
- GParamSpec — implemented as GObject\ParamSpec. These describe properties and are assigned to GObject\Type.
- GObject — implemented as GObject\Object. Base class for all specific classes in GObject hierarchy.
- GSignal — implemented as GObject\Signal. Signal’s are definitions of event slots. Whenever you define new GObject class (using GType) you can specify which event slots it will have, how those events should be handled and, after that, during runtime, trigger events.
So, it’s easy. Define classes, properties, signal slots. Create objects, set properties, emit signals. GObject-for-php takes care of event marshalling, conversion of parameters, etc.
“introspection” branch
After the code above started to work, I branched the code to give another concept a try. These days, a lot of effort in GNOME community goes into GObject Introspection project. They idea is, that bindings developers spend too much time by manually tweaking bindings to every change in C libraries. That’s what PHP-GTK team had to do, for example.
Here’s quotation from project’s web site:
The introspection project solves this by putting all of the metadata inside the GObject library itself, using annotations in the comments. This will lead to less duplicate work from binding authors, and a more reliable experience for binding consumers. Additionally, because the introspection build process will occur inside the GObject libraries themselves, a goal is to encourage GObject authors to consider shaping their APIs to be more binding friendly from the start, rather than as an afterthought.
So, “introspection” branch aims to provide bindings for GObject Introspection infrastructure. The main entry point is GIRepository\load_ns(‘Namespace’) function, which creates php-counterparts of all classes, functions, constants of corresponding GObject namespace dynamically. At least, it will do that one day. With your help :-)
]]>We consider it a minor release, yet, it adds some nice additions to the feature set.
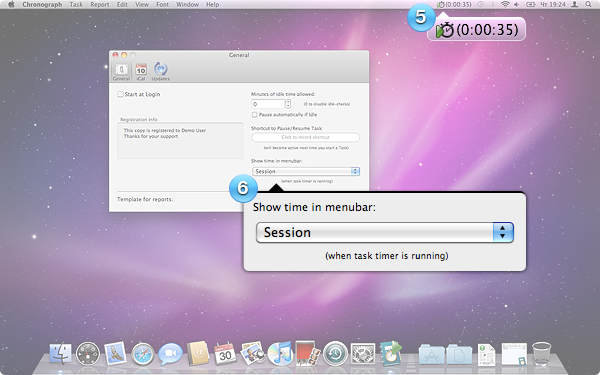
1. Idleness Detection
Did you ever find yourself in situation, when you start time-tracking for the task, walk away from the computer and just forget about it. Then, you find all this time tracked. Sure, you can edit time post factum, but still there’s a need to figure out how much time you actually spent working.
Here’s the solution:
- Open Preferences… and set ”Minutes of idle time allowed” (point 1) to some value larger than zero.
- Whenever you run track time and computer is idle for this amount of minutes a new dialog will jump out (point 2), which will allow you to record only the time before idleness started. Additional notifications will be shown in menubar (point 3) and dock (point 4)
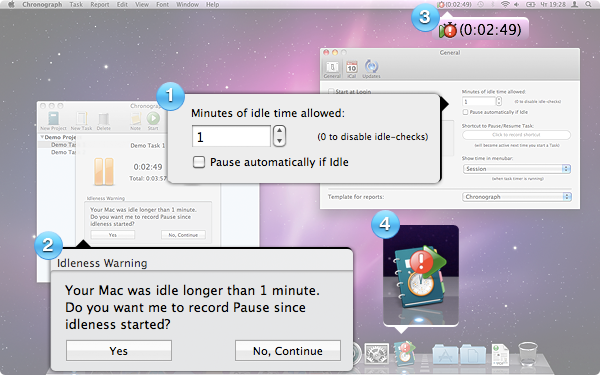
Setting it back to 0 will disable idleness detection.
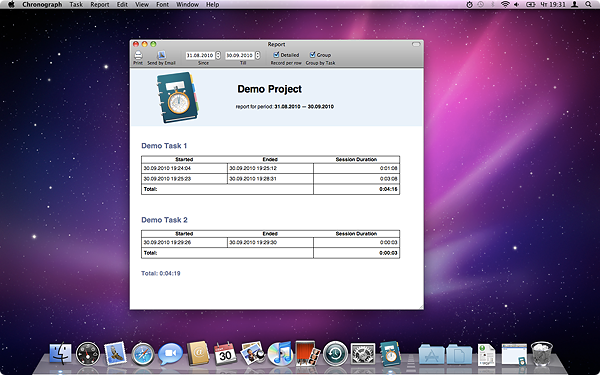
2. New Report Modes
Chronograph 1.3 report facilities allow you to see how much time did you spend daily on Task or Project during requested period.
Chronograph 1.4 goes further and introduces 3 new kinds of reports
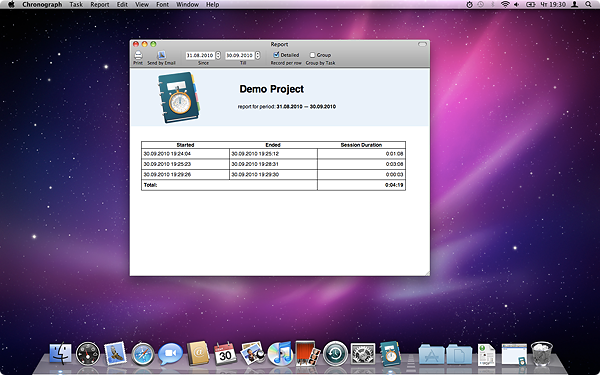
A. Detailed report for Task/Project
shows all sessions of tracked time during requested period
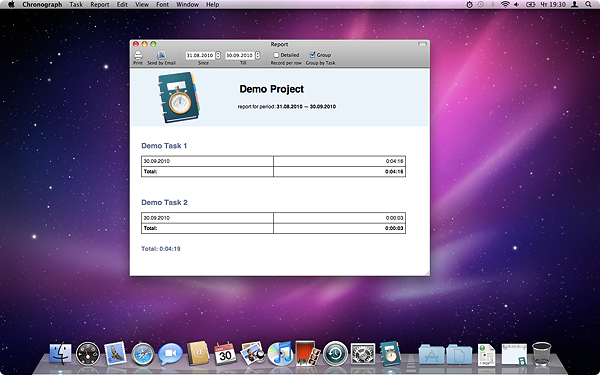
B. Grouped report for Project
shows how much time you spent daily during requested period grouped by Task
C. Grouped Detailed report for Project
shows all sessions of tracked time during requested period grouped by Task
3. Time in menubar area
There’s a new pull down menu in Preferences called ”Show time in menu bar” (point 6). Default is ”none”, which means that only icon is shown in menubar, but you can also chose tho show Session time, total Task time and total Project time. Example is shown on (point 5)
4. Reworked timer sheet
We’re not longer showing spinning circle in timer sheet. Instead, we show you current Session time and either total Task time or total Project time. To switch between task/project time just click on time shown.
You can get this version here: Chronograph 1.4.0.dmg
]]>Pake is a command line utility for executing predefined tasks, inspired by make. It is written in PHP and the tasks are also described in PHP. Pake can be used for compiling projects from different pieces, generating code, preprocessing templates and deploying projects.
If you know Phing, then Pake is a similar thing, but doesn’t use XML, is easier to use and faster.
Here’s the brief Changelog:
- added “interactive mode” (pake -i)
- new helper: pakeMercurial (in addition to pakeSubversion and pakeGit we already had)
- updated sfYaml library
- use copy+unlink instead of rename in pake_rename() to workaround problem of moving files between volumes
- “pake compact” (developers-only) command works again
- added explicit pakePearTask::package_pear_package($file, $target) method
- fixed output-formatting (long texts in exceptions, etc.)
- various packaging fixes
All Pake 1.x versions are compatible with php-5.2. Earlier versions might work, but those are not tested.
If you need automation tool for your project, then Pake might be exactly what you need.
Useful links:
- Pake’s homepage (including documentation)
- Installation instructions
mb_ereg_* family of functions.
There is a common misunderstanding, that mb_ereg_* functions are just unicode counterparts of ereg_* functions: slow and non-powerful. That’s as far from truth as it can be.
mb_ereg_* functions are based on oniguruma regular expressions library. And oniguruma is one of the fastest and most capable regular expression libraries out there. Couple of years ago I made a little speed-test.
Anyway, this time, I was going to tell about it’s usage. PHP-documentation isn’t telling much.
Let’s start with the basic fact: you don’t need to put additional delimeters around your regular exprsssions, when you use mb_ereg_* funcitons. For example:
1 2 3 | |
To execute same search, but in case-insensitive fashion, you should use mb_eregi()
mb_ereg(), mb_eregi() and mb_split() functions use pre-set options in their work. You can check current options and set the new ones using mb_regex_set_options() function. This function is parametrized by string, each letter of which means something.
There are parameters (you can specify several of these at the same time):
- ‘i’:
ONIG_OPTION_IGNORECASE - ‘x’:
ONIG_OPTION_EXTEND - ‘m’:
ONIG_OPTION_MULTILINE - ’s’:
ONIG_OPTION_SINGLELINE - ‘p’:
ONIG_OPTION_MULTILINE | ONIG_OPTION_SINGLELINE - ‘l’:
ONIG_OPTION_FIND_LONGEST - ‘n’:
ONIG_OPTION_FIND_NOT_EMPTY - ‘e’:
eval()resulting code
And there are “modes” (if you specify several of these, the LAST one will be used):
- ‘j’:
ONIG_SYNTAX_JAVA - ‘u’:
ONIG_SYNTAX_GNU_REGEX - ‘g’:
ONIG_SYNTAX_GREP - ‘c’:
ONIG_SYNTAX_EMACS - ‘r’:
ONIG_SYNTAX_RUBY - ‘z’:
ONIG_SYNTAX_PERL - ‘b’:
ONIG_SYNTAX_POSIX_BASIC - ‘d’:
ONIG_SYNTAX_POSIX_EXTENDED
Descriptions of these constants are available in this document: API.txt
So, for example, mb_regex_set_options('pr') is equivalent to mb_regex_set_options('msr') and means:
.should include\n(aka “multiline-match”)^is equivalent to\A,$is equivalent to\Z(aka “strings are single-lined”)- using RUBY-mode
By the way, that is the default setting for mb_ereg_* functions. And, mb_ereg_match and mb_ereg_search families of functions take options-parameter explicitly.
So, back to functions:
1 2 3 4 5 6 7 | |
Ok, these were easy and similar to what you’ve seen in preg_* functions. Now, to something more powerful. The real strength lies in mb_ereg_search_* functions. The idea is, that you can let oniguruma preparse and cache text and/or regexp in its internal buffers. If you do, matching will work a lot faster.
1 2 3 4 5 6 7 8 9 10 11 | |
This is the fastest way of parsing large documents in php, as far as I know.
Notes on charsets. Though, it is often mentioned, that mb_ereg_* functions are “unicode”, it would be more practical to say, that they are encoding-aware. It is a good idea to specify, which encoding you use beore calling oniguruma.
Some options:
1 2 3 4 | |
Check the full list of supported encodings.
]]>Now, some of my readers, are probably asking themselves: what is it all about? why is this bug important? Ok. Let’s find out!
How does browser usually find which server to ask, when you enter URL? Well, at first, it parses out protocol and domain name from URL. For example, if URL is http://www.example.com/page.html then protocol is http and domain name is www.example.com. After that, browser sends request for “A” type record to DNS server and server replies with IP address (or several IP addresses). After that, browser tries to open connection with these addresses one by one, until it finds one which really works. Hopefully, first one will work, but sometimes each one will fail; In this case, browser will show us an error.
“A” records have the following format:
hostname IN A ip-address time-to-live
For basic cases, this scheme seems to work just fine, but it has some inherent flaws, when you start to think about scalability.
It is impossible to map different services on the same domain-name to different servers. For example: I can’t have FTP and HTTP servers responding on example.com and, at the same time, located on different physical machines. My only option would be some kind of router, which would forward requests on different ports to different IP’s.
It is impossible to map service to specific port of server. Browsers just looks for TCP-connection on port 80 while using HTTP, for example.
It is impossible to implement sophisticated load-balancing rules in DNS. Having several A-records in DNS just gives possibility to have equal-load of several machines, nothing fancy.
It is an interesting fact, that all this problems are solved long time ago for one specific protocol called SMTP (yes, the one which delivers emails all around the globe). SMTP uses special kind of DNS-records called “MX” which allow to specify which machine(s) are waiting for SMTP-connections targeted to domain name and allow to specify priority of these machines, so, at first, clients will try to access machines with high priority and in case of problems will fallback to low-priority ones. So, MX records make email-infrastructure seriously more robust and scalable then anything else. Why such special treatment?
“MX” records have the following format:
domainname IN MX priority hostname time-to-live
Here, RFC 2782 comes on scene. Idea of this standard is to achieve similiar flexibility for any protocol used on internet.
“SRV” records allow to specify that specific application protocol, used over specific transport protocol of this domainname is handled by several servers on specific ports with various priority. That is as flexible as it can be. Let me throw some examples:
_http._tcp.example.com. 86400 IN SRV 0 5 81 www1.example.com.
_http._tcp.example.com. 86400 IN SRV 0 5 80 www2.example.com.
_http._tcp.example.com. 86400 IN SRV 1 9 81 www-backup.example.com.
_http._tcp.example.com. 86400 IN SRV 1 1 8000 www-weak-backup.example.com.
These four records tell browser, that:
HTTP-over-TCP connections for “example.com” domain are handled by 4 servers: www1.example.com on port 81, www2.example.com on port 80, www-backup.example.com on port 81 and www-weak-backup.example.com on port 8000.
www1.example.com and www2.example.com have priority “0” (highest), so should be first to try. Both have weight “5”, which means, that they have 50% chance to be selected by client (equal load)
In case both of these are not reachable, browser should check lower-priority servers www-backup.example.com and www-weak-backup.example.com, but www-backup.example com should be preferred in 9 out of 10 cases (it has weight=9, while another one has weight=1).
Sounds pretty cool, but, unfortunately, this technology is still not implemented in any of the browsers. Mozilla(Firefox) has this bug for 10 years, WebKit has this bug for 3+ years and Chromium has this bug since today.
There is no need for special support on webserver-side — that’s a good side of this technology too. Just add relevant records to DNS-server and all compliant clients will see it.
At the moment, SRV-records are widely used by XMPP/Jabber, SIP, LDAP software and Kerberos. I believe, any protocol in use can benefit.
]]>The XSL Cache extension is a modification of PHP’s standard XSL extension that caches the parsed XSL stylesheet representation between sessions for 2.5x boost in performance for sites that repeatedly apply the same transform. API-wise it is compatible with usual XSL extension with two small exceptions:
instead of XSLTProcessor class you should use XSLTCache class.
importStyleshet method has another “signature”: void importStylesheet(string $path, bool $cachesheet=true);
Installation, from now on, should be as simple as ”pecl install xslcache”
]]>Often, while working on software projects, one finds, that there are repetitive tasks, which would be much easier to deal with, if automated. In the C/Unix world, this task is often solved by Make), Java programmers prefer Apache Ant), Ruby programmers use Rake). The fact, which is not commonly known, is, that PHP also has such instrument, and it is called Pake. It was originally created by authors of Symfony framework. Unfortunately, they never wrote any documentation, which killed adoption rates.
To start automating something, you need to create Pakefile.php in the root-directory of your project, define some tasks inside and run them with “pake taskname” from command-line. The good news is, that tasks are defined in PHP language and syntax is quite simple:
<?php
pake_desc(‘FOO task’);
pake_task(‘foo’, ‘bar’);
pake_desc(‘BAR task’);
pake_task(‘bar’, ‘baz’);
pake_desc(‘BAZ task’);
pake_task(‘baz’);
pake_alias(‘default’, ‘foo’); // marking foo as default task
function run_foo($task, $args)
{
echo “foo\n”;
}
function run_bar($task, $args)
{
echo “bar\n”;
}
function run_baz($task, $args)
{
echo “baz\n”;
}
I defined 3 rules, gave them descriptions and specified dependencies. Additionally, I specifed default rule. Now, we can play with this a bit. Create file with this contents, save it somewhere, and point your terminal to the same directory.
`
pake baz bar foo `
What happened? Pake looks for “default” task in the pakefile. We defined “foo” as default. Pake found out, that foo depends on bar, and bar depends on baz. So, Pake runs “baz”, then “bar” and then, finally, “foo”. That is as simple as it can be.
Pake has builtin support for basic file-operations (pake_mkdirs(), pake_copy(), pake_rename(), pake_remove()), which are the powered-up versions of php’s filesystem-functions, templating (pake_replace_tokens()), directory-mirroring (pake_mirror()) and runners for creating PEAR-packages, Phing-commands and Simpletest.
Pake project wasn’t maintained for a while, so I decided to give it a spin (as there is a good chance, that I will be able to use it for my current projects). I imported it’s version history to GitHub. You can find latest version here: http://github.com/indeyets/pake
My plan is to add some generally usable helpers to current branch, write some documentation and then to start work on Pake2 which would use all new features of PHP-5.3 (namespaces, closures, rich SPL).
Git-project is a source for creating pear-package. To build one use the following command:
`
php bin/pake.php release 1.1.0a1 `
it will create “pake-1.1.0a1.tgz” file in the same directory. You can install it with the following command:
`
pear install -f pake-1.1.0a1.tgz `
If you want to grab a prebuild pear-package of pake, you can do it here
]]>Here’s the description from Twitter Data site:
Twitter Data is a simple, open, semi-structured format for embedding machine-readable, yet human-friendly, data in Twitter messages. This data can then be transmitted, received, and interpreted in real time by powerful new kinds of applications built on the Twitter platform. Here is an example Twitter Data message:
I love the #twitterdata proposal! $vote +1
The part with the dollar sign, $vote +1, is a piece of data embedded using the Twitter Data format.
To use php-twitterdata library, download it into the sub-direcory in your project’s directory (or any other place you like) and init the autoloader:
<?php
require ‘php-twitterdata/autoload.php’;
?>
PHP API provided by php-twitterdata has 2 layers. On lower level, there are 3 classes: TwitterData_Message, TwitterData_Frame and TwitterData_Tuple which correspond to parts of data-enabled twitter-message. Message can consist of several Frames, Frame can consist of several Tuples and a “subject”. Objects of each of these classes can be created programmatically and combined in hierarchy. Each of them has “magic” __toString() method, so, to export them as a valid twitter-message, you just need to put objects in string context. Something like this:
<?php
$tuple = new TwitterData_Tuple(‘foo’, ‘bar’);
$frame = new TwitterData_Frame(‘Hello, world!’, array($tuple));
echo $frame;
?>
and the result will be:
Hello, world! $foo bar
If you need to parse Twitter Data messages you should use TwitterData_Parser class. It is a SAX-style parser, with DOM-style export. If all you need is a hierarchy of objects, use it like this:
<?php
$parser = new TwitterData_Parser($text_from_twitter);
$message = $parser->export(); // $message is object of TwitterData_Message class
?>
Otherwise, you can specify another handler-class as a second parameter of constructor. Such class has to implement TwitterData_Parser_CallbackInterface.
Does it all sound too complex? No problem!
php-twitterdata library also includes high-level interface, which consists of 2 simple functions: TwitterData::array_to_TwitterData() and TwitterData::TwitterData_to_array(). First one converts associative array into the string, which can be inserted into twitter-message, and second one takes message-string received from twitter and returns associative array parsed out of tuples from the first frame of message (If you need to get all possible data from message, you will still need to use low-level API).
Example of high-level API:
<?php
TwitterData::TwitterData_to_array(‘Hello, world! $foo bar’);
// array(‘foo’ => ‘bar’);
$message = ‘Hello, world! ‘.TwitterData::array_to_TwitterData(array(‘foo’ => ‘bar’));
// Hello, world! $foo bar
?>
Library has unit-tests, which cover all examples provided on Twitter Data site both on Introduction page and on Examples page and is licensed under MIT-style license.
]]>Their new homes are:
p.s. newest release of MySQL Query Builder has support for subqueries in IN(…) statements
]]>
Just wanted to let you know, that our time-tracking app Chronograph is available for $12.95 from MacZOT today. That’s 50% of our usual price. Please note, that it is a time-limited offer: you can buy Chronograph at this price only on June 30, 2009. Additionally, MacZOT will be giving several free licenses to their subscribers — take your chance.
By the way, we recently released Chronograph 1.3 which has one of the most requested features: iCal integration. Just click one button in preferences and watch how all your tracked time-data appears in iCal-calendar. Add a simple AppleScript and you can integrate Chronograph data into your workflow. With each release Chronograph becomes more mature, but, still, is an extremely easy to use piece of software.
If you were waiting for some special occasion to buy Chronograph license — this is exactly such occasion. Don’t miss it. It is HERE.
relevant links:
[Milk Farm Software, ltd.](http://www.milkfarmsoft.com/)
[Chronograph's home-page](http://www.milkfarmsoft.com/chronograph.php)
[Download Chronograph 1.3](http://s3.amazonaws.com/milkfarmsoft/Chronograph%201.3.0.dmg)
PHP-FPM is “deciphered” as “PHP FastCGI Process Manager” and is a patch for php to greatly improve FastCGI SAPI usage in production. It adds a bunch of additional features to php’s fastcgi such as: easy php-process daemonization (with ability to specify uid/gid/chroot/log-file), safe php-processes restart (without losing requests), custom error-handling and accelerated file-upload support (requires additional support from web-server).
There’s not much documentation in english, currently, but, again, there is a good chance that it will be added really soon.
]]>Today, I am glad to announce the release of my new product: Chronograph. Chronograph is one of those tools, that I wrote for myself, because everything else out there felt like nonsense. Either too complicated, or too ugly. Anyway, Chronograph — is a time tracking application. Basically, there are Projects, which consist of Tasks. You can select task and start the timer. Then you do the job, stop the timer and move on to the next task. Chronograph keeps stats on the time spent and you can create reports (basic, for now) based on them.
I am trying to make application, which would feel “right”, and looks like the direction is correct.

If you have any comments, ideas regarding Chronograph let me know in comments, or using email: [email protected]
Thanks :)
]]>Sometimes it feels completely counter-intuitive and you just end up manually hiding some files.
Common end-user solution is just sticking to the package-root provided by distribution (usually “/usr”), but that is not an option for developer, who needs to test different combinations of bleeding-edge apps.
How do you manage this stuff?
Example. I need to build php6 (installation prefix /opt/php6) with:
iconv from /sw (whle there is other iconv in /usr)
libxml from /usr (while there is other libxml in /sw)
icu from /sw/local (while there are pieces of other icu’s in /sw and /usr)
In reality, there are more libs involved, and complexity arises, when these different libs are needed by the same components of php. I start thinking, that I should create some special package-root and just symlink every needed library in it. And just give it as the only package-root to php. Seems like a complex task, while considering all dependencies.
In my ideal world, there would be no name-resolution at all, compiler would just require exact position of library (which would be represented by the single file)
]]>LLVM 2.3 is supposed to be released today (what’s new?)
WWDC 2008 is starting today
I wonder, if that is coincidence
]]>UNRELIABLE_MESS
RELIABLE_MESS
FIFO_MESS
CAUSAL_MESS
AGREED_MESS
SAFE_MESS
REGULAR_MESS
p.s. freshly released php binding is here
]]>May the force be with you! ;)
]]>RFC2821 (SMTP) tells: The maximum total length of a text line including the
Actually, there is even a PHP-bug reported, regarding this, but PHP obviously can’t do anything to help the situation
The solution is really simple: if there is a chance, that lines of your emails would be longer than 990 bytes encode body using base-64. The easiest way to do it for emails without attachments, in php is to use mb_send_mail() function instead of mail(), as it will apply encoding automatically.
]]>TextMate:
Command + Option + Left/Right
Skype:
Command + Shift + Left/Right
Adium, Firefox:
Command + Left/Right
Colloquy, Firefox:
Command + Up/Down
Opera, Safari, Terminal:
Command + Shift + [/]
Dear Santa, please, bring me Mk 41 next christmas, so I can fix this world.
]]>First, and most important: a lot of stability and consistency fixes (previous release wasn’t properly dealing with some kinds of number-like strings and with mixed-keys arrays). This release is HIGHLY recommended to anyone who uses syck-php in production. I was using this version for several weeks as a server-to-server exchange format under heavy load and coudn’t be satisfied more.
I started to dive into object-serialization and unserialization topics. Any object which implements Serializable interface can be dumped into yaml-document now. It will be stored using !php/object::ClassName signature. And, of course, you would be able load the object afterwards. Important: at the moment of loading yaml-file, all of the classes mentioned in it have to be either declared, or be available to php’s autoload mechanism.
I also implemented loading of objects with !php/array::ClassName and !php/hash::ClassName signatures. These have to implement ArrayAccess interface. Unfortunately, I didn’t implement dumping of such objects yet. That is planned for the next releae.
As always, I am open to hear any of your comments and bug-reports.
]]>Top reasons:
1. FastCGI process can be run using the actual uid of user who creates the files (no need to allow group-readability of files)
2. Apache2 can be run in multithreaded-mode (aka ”worker mpm”)
3. It is much easier to switch to any other server (fastcgi is an industry standard and works with any web-server software I know of)
4. It is much easier to scale — fastcgi-application can be moved to another physical server and http-server will still be able to talk with it
FastCGI is about flexibility and it deserves a lot of good words not only in IIS context :)
]]>I guess I can put a badge “Powered by OpenSolaris” somewhere around ;)
]]>Problem:
on systems with 32-bit integers, ip2long() returns values from -2147483648 to 2147483647
on systems with 64-bit integers, ip2long() returns values from 0 to 42949672945
Which means, that if you were using INT as a storage type on 32-bit server, you will need to change that field to be UNSIGNED INT (or BIGINT) on 64-bit server.
There is no simple migration, sorry.
p.s. similiar problems can appear in other intger-related functions too
]]>al_n @ [link]:
I re tested syck and it does make a BIG difference. I tested with a yaml file of about 200,000 lines which I killed after an hour while using spyc. The same file was loaded with syck in about 5 minutes!!!
p.s. I hope to find some time, to release an updated pecl-package of syck really soon. Please, remind me to do it ;)
]]>On the other hand, it reminds me, that I should release the new version…
]]>This is the funniest introduction to lambda-calculus ever. (saw it at #d channel at freenode)
]]>Ok, it seems that MySQL AB is finally committing to fix up PDO_MySQL and to generally accept the fact that PDO is the future. Of course mysqli will also be actively maintained. But they will also make mysqlnd play nicely with PDO etc.
They have a budget allocated for PDO development. They will soon assign a developer on this I am told. As part of this effort it is expected that the entire PDO test suite will also benefit.
Furthermore they have allocated someone from the doc team to check over the ext/mysql and ext/mysqli docs. I will poke the relevant people at regular intervals, that any MySQL specific features in PDO will make it into the docs.
I was waiting 2 years (at least) for this to happen. Thanks for the good news, Lukas :)
]]>Makes me think, that I should really-really get some old mac-mini and install Haiku on it. At least, I can program some fancy Jukebox out of it :)
ohloh.net: The World’s Oldest Source Code Repositories
Hey! I was only 1 year old, when they started to use version control! :-o
I love D language, I love LLVM — they make such a beautiful couple. Project is not complete, yet, but it already works for simple cases. Author needs any man-power he can get: spread the word, please.
Sam Ruby noticed CouchDB: Ascetic Database Architectures
It brought some more attention to CouchDB, which is really-really deserved. CouchDB is a document-oriented non-relational database written by Damien Katz and Jan Lehnardt in erlang, which has JSON, PHP and Ruby APIs (the number of APIs grows each day).
Opera released 3 public alpha-versions of their 9.5 series
Finally, Opera looks like a native application on mac. It is lightning fast with a new javascript-engine and heavily optimized UI code. I already use 9.5 on daily basis without problems, but your mileage may differ — it is an alpha-version, after all. Get it here
PHP 5.3 will have Late Static Binding
LSB will allow static methods to know about inheritance (to know, on which of the descendant-classes the method was actually called). Which means, that it will be possible to make a good-looking ActiveRecord implementation, after all these years.
]]>The texts and downloads are there — everything should be working fine. I didn’t do any software updates this time — just republished old archives (they still work) to the redesigned site.
So, in case you were missing my software, you can grab it again, now :)
Plans:
release ”Ping-Pong” — the new piece of software by us
release universal binary of Separator
check if open-source stuff needs to be updated
p.s. the plans will probably be realized in mid-september, as I am going to take a vacation in a week
]]>I mean:
× instead of *****
→ instead of ->
↠instead if <-
≠instrad of !=
≤ and ≥ instead of <= and >=
This list can be continued more and more…
I perfectly understand the roots of current situation and I don’t ask to use ONLY unicode-symbols, but I ask language-manufacturers to allow this.
]]>Changelog:
fixed handling of invalid merge-references [reported by Sascha Kettler]
fixed tsrm-incompatibility introduced in 0.9
added support for timestamps in syck_load (thanks to Derick for a hint)
added support for DateTime in syck_dump
fixed dumping of associative-arrays
Update is highly recommended for everyone
]]>MacOS would be able to use non-gcc by default (there are some comments, here, describing why it is a good thing)
MacOS would become really-really cross-platform
Something like: ` $timestamp = ‘2007-07-07 07:07:07’; $timezone = ‘+0300’;
$obj = new DateTime($timestamp, new DateTimeZone(????)); `
I need this, to add proper support for YAML-timestamps in my syck extension.
In YAML, timestamps have several representations:
canonical: 2001-12-15T02:59:43.1Z
valid iso8601: 2001-12-14t21:59:43.10-05:00
space separated: 2001-12-14 21:59:43.10 -5
no time zone (Z): 2001-12-15 2:59:43.10
date (00:00:00Z): 2002-12-14
As you can see, in each case timezone is represented by numeric, while PHP expects me to specify timezone as a toponym…
]]>This is an extension for reading and writing YAML-files.
YAMLâ„¢ (rhymes with “camel”) is a straightforward machine parsable data serialization format designed for human readability and interaction with scripting languages. YAML is optimized for data serialization, configuration settings, log files, Internet messaging and filtering.
YAML is extensively used by Symfony Framework and there is also a component for Zend Framework in development. But it’s use is not limited by something big — YAML is a perfect solution for configuration-files (way more comfortable than Ini or XML).
Some time ago, I posted installation instructions. Here is the updated version:
Install Syck-library using your favorite package-manager (stable 0.55 version will do) [debian, freebsd, etc.]
pecl install syck-beta
restart Apache of Fast-CGI process (if needed)
Tell me how it works for you :)
]]>
5 July 2007 — A consortium of PHP developers has announced today that several leading Open Source PHP projects will be dropping support for older versions of PHP in upcoming releases of their software as of February 5, 2008 as part of a joint effort to move the PHP developer community fully onto PHP version 5.
The Symfony, Typo3, phpMyAdmin, Drupal, Propel, and Doctrine projects have all announced that their next release after February 5, 2008 will require PHP version 5.2 as part of a coordinated effort at GoPHP5.org, and have issued an open invitation to any other PHP projects and applications, both open source and proprietary, that want to participate in the effort.
Full press-release is here
]]>Supported datatypes:
associative arrays
indexed arrays
strings
integers
floats
booleans
null
Objects are simply ignored now, though I am planning to add support for them later. See TODO for details.
Example, to give you idea:
$data = array(
'items' => array(
'item 1',
'item 2'
),
'count' => 2
);
echo syck_dump($data);
take a look at my previous yaml-post for installation instructions.
Let me know how this works for you :)
p.s. should I change the name of that function? :-/
]]>As usual, if you have any good or bad feedback — let me know :)
]]>MySQL Query Builder is a set of PHP5 Classes which can… (surprise!) build correct MySQL5 queries for use with PDO’s prepare/execute. This things rocks really hard if you need to implement some kind of database layer (I implemented ActiveRecord this way) in your app and building queries in dynamics.
]]>At first, there was Netscape and their first spec which wasn’t Y2K-compliant. Then, there was 1997 and the new spec: RFC2109 which fixed Y2K problem as well as couple of other minor issues — this is the specification which is used by the major part of browsers, these days.
Then, in the year of 2000 RFC2965, which brings some quite interesting stuff. Unfortunately, this one is not supported by any browsers but Opera. (one more bit in a pile named “Opera is the most innovative standards-compliant browser”)
mnot has a nice article about support of cookies standards by browsers.
Now, about server-side…
PHP supports RFC2109 enhanced version of the Netscape standard (as mentioned in comments) and (since 5.2) microsoft’s “http-only” extension.
Python has support for 2965, but it is turned off by default.
Ruby seems to support 2965, but I didn’t test it, neither found enough evidence
I wonder which way should I implement this… Should I try detecting client capabilities and send cookies in corresponding format (if there is ‘Cookie2: $Version=1’ header I use SetCookie2, else I use SetCookie)? Or should I leave the this decision to the user?
]]>Hello world! #22960
Memory usage: 232312
Peak Memory usage: 275352
Memory usage last growed at request#71
Looks good enogh for me :)
p.s. weekend is coming — I will be posting some more-interesting stuff
]]>I am currently thinking about proper object hierarchy and, actually, I changed it completely 3 times already in my thoughts. I finally “see the light”â„¢ and will implement it on a weekend. I think about converting SCGI-part to a simple “driver” and move all http-related stuff to a separate driver-agnostic set of classes (Probably, that would be a class per kind of http-request and a class per kind of http-response). This way, I would be able to implement FastCGI as anther driver without altering applications. If you have any better ideas — let me know.
For now, I made another example application. This time, with some benchmarking in thoughts. Here it is.
This example supposes, that you have ezcomponents folder on the one level with the svn-checked-out “trunk” of my googlecode-project. And, you can start “runner.php” both as SCGI-server (using CLI) or as usual mod_php/(fast)cgi application. The idea was to see if there will be any noticeable speed difference between approaches. But… it showed the other thing :)
I used ezcGraph/classtrees_Graph.html) in my application and noticed a serious memory-leaking. Obviously, ezcGraph has the forementioned in comments problem with cycled references. The solution is, to add some kind of ”public function clean()” method, which would remove references in the object, and objects which were auto-generated by it, so it would later be cleaned-up by a garbage-collector. I implemented a quick-fix locally and it did help to some degreee, but I definitely missed some references, so it still leaked. I think that someone who knows internals of eZComponents better should do it.
Derick? Anyone? Can this be done?
]]>Long story: Some time ago I was ranting about PHP and it’s “way” of handling FastCGI. The idea is to have persistent PHP-application which would handle requests from inside. This would allow us have “real” persistent cache in application (persistent connection to arbitary resources, preparsed XSLT’s in memory) and reply to queries really fast as we wouldn’t need to load all the classes on each request (classes would be loaded only once, during app initialization). And no, APC and similiar technologies do not completely solve this problem.
I finally found some time (and inspiration) to do something in direction of implementing FastCGI the way I see it. Initially, I was going to implement FastCGI-functions in php-extension, but that would require more time than I currently have, so I started with a simplier task: I implemented SCGI protocol (which is way simplier than FastCGI) in pure php-code (which is easier, again, and let’s me change API faster, during development).
This thing already works and you can test it if you have SCGI-enabled server (apache and lighttpd will do) and PHP 5.2.1+ (cli). At first, you need to get latest sources from my google-code project. Sources come with an example.
Some comments to ease understanding:
Start by including SCGI/autoload.php file — it will take care of including all SCGI-classes
Create your class by extending SCGI_Application. It needs to have two methods: public function __construct and protected function requestHandler. Constructor should call parent::__construct optionally with the stream-url. By default, application will listen on tcp://127.0.0.1:9999.
requestHandler is the function which is called by application on every request. This is the point where most of the things should happen. Request-data is available from $this->request() and Response-data should be given to $this->response(). See example for details
To see some result you need to tell your web-server, where your application’s socket is. Example for Lighttpd is available in repository
Warning: This is the pre-pre-release. API will be changing.
UPDATE: Code of this project was moved to github: http://github.com/indeyets/appserver-in-php
]]>BeOS was always about C++, opposing UNIX’es, MacOS’es and Windows’es choice of C (well, formally, windows had C++ api, but, still, it was very C-ish in it’s essence). Years passed, MacOS switched to Objective-C, Windows switched to C#. Both of these languages are higher-level OOP languages which have some kind of memory-management. C++, while it has some advantages, still is not as easy and dynamic as these languages are.
Unfortunately, both Objective-C and C# are developed by Apple and Microsoft (correspondingly) behind the closed-doors.
So, what is the alternative? I see two of them:
D is good, as it makes a step from C++ to real life, but is still low-levelish, by design. memory management will solve some headaches, but programming in it won’t be as fun as it can be. I like to see D as a language for writing libraries.
Smalltalk, on the other hand, is a high-level dynamic language which is just what is needed. Once you “taste” the fruit of dynamic languages you wouldn’t want to code high-level tasks in static-languages anymore (static is extremely good in low-level, though). To give you a brief idea on what all this is about, there is a nice article by a game developer who switched from C++ to Smalltalk: Learning to Talk: Introduction to Talking.
Further reading:
Ambrai Smalltalk (Smalltalk for MacOS-X)
F-Script (Smalltalk-based scripting environment for Cocoa)
Comparison of programming languages @ wikipedia
It looks so damn elegant
]]>Here is a very nice introduction to Boost.Foreach.
(If you don’t know…) Fink is a project that brings the full world of Unix Open Source software to Mac OS X.
]]>